这里是原文的中文翻译,精简了部分内容。
进程与线程
进程(Process)是一个操作系统抽象概念,它将多种资源组合在一起:
- 地址空间
- 一个或多个线程
- 打开的文件
- 套接字(Sockets)
- 信号量(Semaphores)
- 共享内存区域
- 定时器
- 信号处理程序
- 许多其他资源和状态信息
所有这些信息都被归纳在进程控制块(PCB)中。在 Linux 中,这就是 struct task_struct。
struct task_struct
让我们仔细看看 struct task_struct。我们可以直接查看源代码,但在这里我们将使用一个名为 pahole 的工具(dwarves 安装包的一部分),以便对该结构有一些深入了解:
$ pahole -C task_struct vmlinux
struct task_struct {
struct thread_info thread_info; /* 0 8 */
volatile long int state; /* 8 4 */
void * stack; /* 12 4 */
...
/* --- cacheline 45 boundary (2880 bytes) --- */
struct thread_struct thread __attribute__((__aligned__(64))); /* 2880 4288 */
/* size: 7168, cachelines: 112, members: 155 */
/* sum members: 7148, holes: 2, sum holes: 12 */
/* sum bitfield members: 7 bits, bit holes: 2, sum bit holes: 57 bits */
/* paddings: 1, sum paddings: 2 */
/* forced alignments: 6, forced holes: 2, sum forced holes: 12 */
} __attribute__((__aligned__(64)));如你所见,这是一个相当大的数据结构:大小接近 8KB,包含 155 个字段。
线程 (Threads)
线程是内核进程调度器用来允许应用程序运行 CPU 的基本单位。线程具有以下特征:
- 每个线程都有自己的栈,它与寄存器值一起决定了线程的执行状态
- 线程在进程的上下文中运行,同一进程中的所有线程共享资源
- 内核调度的是线程而不是进程,用户级线程(如纤程、协程等)在内核层是不可见的
典型的线程实现是将线程实现为独立的数据结构,然后链接到进程数据结构。例如,Windows 内核就使用了这种实现方式:
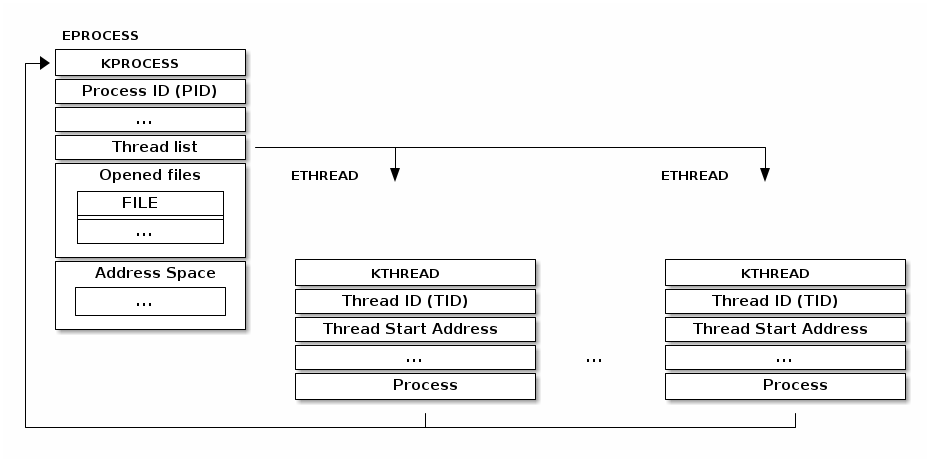
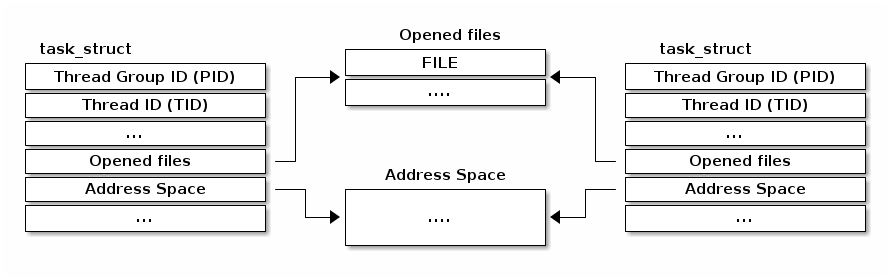
Linux 对线程使用了不同的实现方式。基本单位称为任务(task,因此有 struct task_struct),它既用于线程也用于进程。它没有将资源嵌入到任务结构中,而是拥有指向这些资源的指针。
因此,如果两个线程属于同一个进程,它们将指向相同的资源结构实例。如果两个线程处于不同的进程中,它们将指向不同的资源结构实例。
clone 系统调用
在 Linux 中,新的线程或进程是通过 clone() 系统调用创建的。fork() 系统调用和 pthread_create() 函数都使用了 clone() 的实现。
它允许调用者决定哪些资源应与父进程共享,哪些应被复制或隔离:
- CLONE_FILES - 与父进程共享文件描述符表
- CLONE_VM - 与父进程共享地址空间
- CLONE_FS - 与父进程共享文件系统信息(根目录、当前目录)
- CLONE_NEWNS - 不与父进程共享挂载命名空间
- CLONE_NEWIPC - 不与父进程共享 IPC 命名空间(System V IPC 对象、POSIX 消息队列)
- CLONE_NEWNET - 不与父进程共享网络命名空间(网络接口、路由表)
例如,如果调用者使用了 CLONE_FILES | CLONE_VM | CLONE_FS,那么实际上就创建了一个新线程。如果没有使用这些标志,则创建一个新进程。
命名空间与“容器”
“容器”是一种轻量级的虚拟机形式,它们共享同一个内核实例,这与普通虚拟化不同,普通虚拟化中管理程序(hypervisor)运行多个虚拟机,每个虚拟机都有自己的内核实例。
容器技术的例子包括 LXC(允许运行轻量级“VM”)和 docker(一种用于运行单个应用程序的专用容器)。
容器建立在少数几个内核功能之上,其中之一就是命名空间(namespaces)。它们允许隔离那些原本全局可见的不同资源。例如,如果没有容器,所有进程在 /proc 中都是可见的。有了容器,一个容器中的进程对其他容器(在 /proc 中或被杀死的权限)将是不可见的。
为了实现这种分区,使用了 struct nsproxy 结构来对我们要分区的资源类型进行分组。它目前支持 IPC、网络、cgroup、挂载、PID、时间命名空间。例如,网络接口列表不再是全局列表,而是 struct net 的一部分。系统使用默认的命名空间 (init_net) 初始化,默认情况下所有进程都将共享此命名空间。当创建一个新的命名空间时,会创建一个新的网络命名空间,然后新进程可以指向该新命名空间,而不是默认的那个。
访问当前进程
访问当前进程是一个频繁的操作:
- 打开文件需要访问
struct task_struct的 file 字段 - 映射新文件需要访问
struct task_struct的 mm 字段 - 超过 90% 的系统调用需要访问当前进程结构,因此它必须很快
current宏可用于访问当前进程的struct task_struct
为了支持多处理器配置中的快速访问,使用了一个每 CPU (per CPU) 变量来存储和检索指向当前 struct task_struct 的指针:
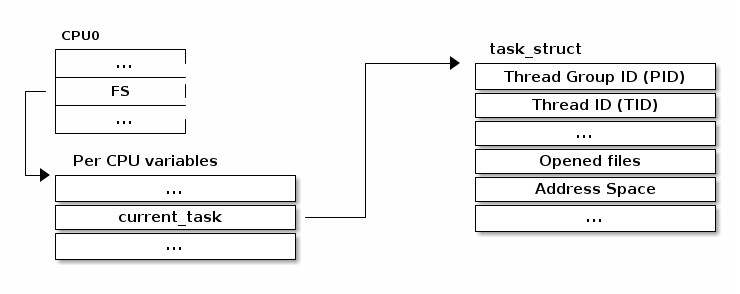
以前,current 宏的实现使用了以下序列:
/* how to get the current stack pointer from C */
register unsigned long current_stack_pointer asm("esp") __attribute_used__;
/* how to get the thread information struct from C */
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)(current_stack_pointer & ~(THREAD_SIZE – 1));
}
#define current current_thread_info()->task上下文切换 (Context switching)
下图显示了 Linux 内核上下文切换过程的概览:
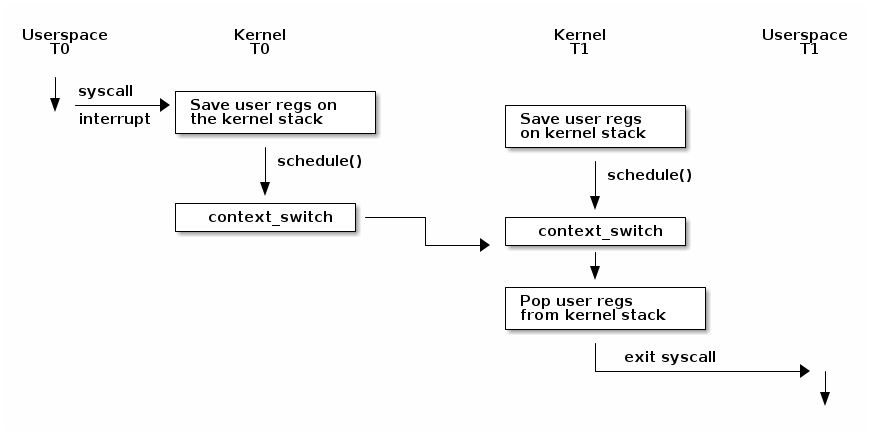
请注意,在发生上下文切换之前,必须先进行内核转换(kernel transition),可以通过系统调用或中断来实现。此时,用户空间寄存器被保存在内核栈上。在某个时刻,schedule() 函数会被调用,它可以决定必须从 T0 切换到 T1(例如,因为当前线程正在阻塞等待 I/O 操作完成,或者因为它分配的时间片已耗尽)。
此时,context_switch() 将执行特定于架构的操作,并在需要时切换地址空间:
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
prepare_task_switch(rq, prev, next);
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
/*
* kernel -> kernel lazy + transfer active
* user -> kernel lazy + mmgrab() active
*
* kernel -> user switch + mmdrop() active
* user -> user switch
*/
if (!next->mm) { // to kernel
enter_lazy_tlb(prev->active_mm, next);
next->active_mm = prev->active_mm;
if (prev->mm) // from user
mmgrab(prev->active_mm);
else
prev->active_mm = NULL;
} else { // to user
membarrier_switch_mm(rq, prev->active_mm, next->mm);
/*
* sys_membarrier() requires an smp_mb() between setting
* rq->curr / membarrier_switch_mm() and returning to userspace.
*
* The below provides this either through switch_mm(), or in
* case 'prev->active_mm == next->mm' through
* finish_task_switch()'s mmdrop().
*/
switch_mm_irqs_off(prev->active_mm, next->mm, next);
if (!prev->mm) { // from kernel
/* will mmdrop() in finish_task_switch(). */
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}
}
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
prepare_lock_switch(rq, next, rf);
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}然后它将调用特定于架构的 switch_to 实现来切换寄存器状态和内核栈。注意,寄存器保存在栈上,而栈指针保存在任务结构中:
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to_asm((prev), (next))); \
} while (0)
/*
* %eax: prev task
* %edx: next task
*/
.pushsection .text, "ax"
SYM_CODE_START(__switch_to_asm)
/*
* Save callee-saved registers
* This must match the order in struct inactive_task_frame
*/
pushl %ebp
pushl %ebx
pushl %edi
pushl %esi
/*
* Flags are saved to prevent AC leakage. This could go
* away if objtool would have 32bit support to verify
* the STAC/CLAC correctness.
*/
pushfl
/* switch stack */ movl %esp, TASK_threadsp(%eax) movl TASK_threadsp(%edx), %esp
#ifdef CONFIG_STACKPROTECTOR
movl TASK_stack_canary(%edx), %ebx
movl %ebx, PER_CPU_VAR(stack_canary)+stack_canary_offset
#endif
#ifdef CONFIG_RETPOLINE
/*
* When switching from a shallower to a deeper call stack
* the RSB may either underflow or use entries populated
* with userspace addresses. On CPUs where those concerns
* exist, overwrite the RSB with entries which capture
* speculative execution to prevent attack.
*/
FILL_RETURN_BUFFER %ebx, RSB_CLEAR_LOOPS, X86_FEATURE_RSB_CTXSW
#endif
/* Restore flags or the incoming task to restore AC state. */
popfl
/* restore callee-saved registers */
popl %esi
popl %edi
popl %ebx
popl %ebp
jmp __switch_to SYM_CODE_END(__switch_to_asm)
.popsection你会注意到指令指针(IP)没有被显式保存。这是不需要的,因为:
- 任务总是会在该函数中恢复
schedule()(context_switch()总是内联的)调用者的返回地址保存在内核栈上- 使用
jmp执行__switch_to(),这是一个函数,当它返回时,它将从栈中弹出原始(下一个任务的)返回地址
阻塞和唤醒任务
任务状态
下图显示了任务(线程)状态以及它们之间可能的转换:
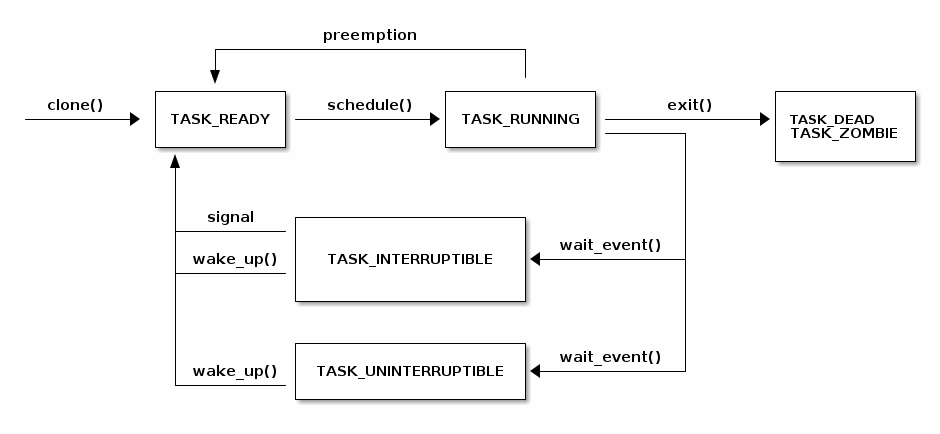
阻塞当前线程
阻塞当前线程是我们需要执行的一项重要操作,以实现高效的任务调度——我们希望在 I/O 操作完成时运行其他线程。
为了实现这一点,会发生以下操作:
- 将当前线程状态设置为 TASK_UINTERRUPTIBLE 或 TASK_INTERRUPTIBLE
- 将任务添加到等待队列
- 调用调度器,调度器将从 READY(就绪)队列中选择一个新任务
- 执行到新任务的上下文切换
下面是一些 wait_event 实现的片段。请注意,等待队列是一个带有一些额外信息(如指向任务结构的指针)的列表。
另请注意,为了确保 wait_event 和 wake_up 之间不会发生死锁,投入了大量精力:任务在检查 condition 之前被添加到列表中,在调用 schedule() 之前会检查信号。
/**
* wait_event - sleep until a condition gets true
* @wq_head: the waitqueue to wait on
* @condition: a C expression for the event to wait for
*
* The process is put to sleep (TASK_UNINTERRUPTIBLE) until the
* @condition evaluates to true. The @condition is checked each time
* the waitqueue @wq_head is woken up.
*
* wake_up() has to be called after changing any variable that could
* change the result of the wait condition.
*/
#define wait_event(wq_head, condition) \
do { \
might_sleep(); \
if (condition) \
break; \
__wait_event(wq_head, condition); \
} while (0)
#define __wait_event(wq_head, condition) \
(void)___wait_event(wq_head, condition, TASK_UNINTERRUPTIBLE, 0, 0, \
schedule())
/*
* The below macro ___wait_event() has an explicit shadow of the __ret
* variable when used from the wait_event_*() macros.
*
* This is so that both can use the ___wait_cond_timeout() construct
* to wrap the condition.
*
* The type inconsistency of the wait_event_*() __ret variable is also
* on purpose; we use long where we can return timeout values and int
* otherwise.
*/
#define ___wait_event(wq_head, condition, state, exclusive, ret, cmd) \
({ \
__label__ __out; \
struct wait_queue_entry __wq_entry; \
long __ret = ret; /* explicit shadow */ \
\
init_wait_entry(&__wq_entry, exclusive ? WQ_FLAG_EXCLUSIVE : 0); \
for (;;) { \
long __int = prepare_to_wait_event(&wq_head, &__wq_entry, state);\
\
if (condition) \
break; \
\
if (___wait_is_interruptible(state) && __int) { \
__ret = __int; \
goto __out; \
} \
\
cmd; \
} \
finish_wait(&wq_head, &__wq_entry); \
__out: __ret; \
})
void init_wait_entry(struct wait_queue_entry *wq_entry, int flags)
{
wq_entry->flags = flags;
wq_entry->private = current;
wq_entry->func = autoremove_wake_function;
INIT_LIST_HEAD(&wq_entry->entry);
}
long prepare_to_wait_event(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry, int state)
{
unsigned long flags;
long ret = 0;
spin_lock_irqsave(&wq_head->lock, flags);
if (signal_pending_state(state, current)) {
/*
* Exclusive waiter must not fail if it was selected by wakeup,
* it should "consume" the condition we were waiting for.
*
* The caller will recheck the condition and return success if
* we were already woken up, we can not miss the event because
* wakeup locks/unlocks the same wq_head->lock.
*
* But we need to ensure that set-condition + wakeup after that
* can't see us, it should wake up another exclusive waiter if
* we fail.
*/
list_del_init(&wq_entry->entry);
ret = -ERESTARTSYS;
} else {
if (list_empty(&wq_entry->entry)) {
if (wq_entry->flags & WQ_FLAG_EXCLUSIVE)
__add_wait_queue_entry_tail(wq_head, wq_entry);
else
__add_wait_queue(wq_head, wq_entry);
}
set_current_state(state);
}
spin_unlock_irqrestore(&wq_head->lock, flags);
return ret;
}
static inline void __add_wait_queue(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry)
{
list_add(&wq_entry->entry, &wq_head->head);
}
static inline void __add_wait_queue_entry_tail(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry)
{
list_add_tail(&wq_entry->entry, &wq_head->head);
}
/**
* finish_wait - clean up after waiting in a queue
* @wq_head: waitqueue waited on
* @wq_entry: wait descriptor
*
* Sets current thread back to running state and removes
* the wait descriptor from the given waitqueue if still
* queued.
*/
void finish_wait(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry)
{
unsigned long flags;
__set_current_state(TASK_RUNNING);
/*
* We can check for list emptiness outside the lock
* IFF:
* - we use the "careful" check that verifies both
* the next and prev pointers, so that there cannot
* be any half-pending updates in progress on other
* CPU's that we haven't seen yet (and that might
* still change the stack area.
* and
* - all other users take the lock (ie we can only
* have _one_ other CPU that looks at or modifies
* the list).
*/
if (!list_empty_careful(&wq_entry->entry)) {
spin_lock_irqsave(&wq_head->lock, flags);
list_del_init(&wq_entry->entry);
spin_unlock_irqrestore(&wq_head->lock, flags);
}
}唤醒任务
我们可以使用 wake_up 原语来唤醒任务。唤醒任务执行以下高级操作:
- 从等待队列中选择一个任务
- 将任务状态设置为 TASK_READY
- 将任务插入调度器的 READY(就绪)队列
- 在 SMP 系统上,这是一个复杂的操作:每个处理器都有自己的队列,队列需要平衡,CPU 需要被信号通知
#define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL)
/**
* __wake_up - wake up threads blocked on a waitqueue.
* @wq_head: the waitqueue
* @mode: which threads
* @nr_exclusive: how many wake-one or wake-many threads to wake up
* @key: is directly passed to the wakeup function
*
* If this function wakes up a task, it executes a full memory barrier before
* accessing the task state.
*/
void __wake_up(struct wait_queue_head *wq_head, unsigned int mode,
int nr_exclusive, void *key)
{
__wake_up_common_lock(wq_head, mode, nr_exclusive, 0, key);
}
static void __wake_up_common_lock(struct wait_queue_head *wq_head, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
unsigned long flags;
wait_queue_entry_t bookmark;
bookmark.flags = 0;
bookmark.private = NULL;
bookmark.func = NULL;
INIT_LIST_HEAD(&bookmark.entry);
do {
spin_lock_irqsave(&wq_head->lock, flags);
nr_exclusive = __wake_up_common(wq_head, mode, nr_exclusive,
wake_flags, key, &bookmark);
spin_unlock_irqrestore(&wq_head->lock, flags);
} while (bookmark.flags & WQ_FLAG_BOOKMARK);
}
/*
* The core wakeup function. Non-exclusive wakeups (nr_exclusive == 0) just
* wake everything up. If it's an exclusive wakeup (nr_exclusive == small +ve
* number) then we wake all the non-exclusive tasks and one exclusive task.
*
* There are circumstances in which we can try to wake a task which has already
* started to run but is not in state TASK_RUNNING. try_to_wake_up() returns
* zero in this (rare) case, and we handle it by continuing to scan the queue.
*/
static int __wake_up_common(struct wait_queue_head *wq_head, unsigned int mode,
int nr_exclusive, int wake_flags, void *key,
wait_queue_entry_t *bookmark)
{
wait_queue_entry_t *curr, *next;
int cnt = 0;
lockdep_assert_held(&wq_head->lock);
if (bookmark && (bookmark->flags & WQ_FLAG_BOOKMARK)) {
curr = list_next_entry(bookmark, entry);
list_del(&bookmark->entry);
bookmark->flags = 0;
} else
curr = list_first_entry(&wq_head->head, wait_queue_entry_t, entry);
if (&curr->entry == &wq_head->head)
return nr_exclusive;
list_for_each_entry_safe_from(curr, next, &wq_head->head, entry) {
unsigned flags = curr->flags;
int ret;
if (flags & WQ_FLAG_BOOKMARK)
continue;
ret = curr->func(curr, mode, wake_flags, key);
if (ret < 0)
break;
if (ret && (flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
if (bookmark && (++cnt > WAITQUEUE_WALK_BREAK_CNT) &&
(&next->entry != &wq_head->head)) {
bookmark->flags = WQ_FLAG_BOOKMARK;
list_add_tail(&bookmark->entry, &next->entry);
break;
}
}
return nr_exclusive;
}
int autoremove_wake_function(struct wait_queue_entry *wq_entry, unsigned mode, int sync, void *key)
{
int ret = default_wake_function(wq_entry, mode, sync, key);
if (ret)
list_del_init_careful(&wq_entry->entry);
return ret;
}
int default_wake_function(wait_queue_entry_t *curr, unsigned mode, int wake_flags,
void *key)
{
WARN_ON_ONCE(IS_ENABLED(CONFIG_SCHED_DEBUG) && wake_flags & ~WF_SYNC);
return try_to_wake_up(curr->private, mode, wake_flags);
}
/**
* try_to_wake_up - wake up a thread
* @p: the thread to be awakened
* @state: the mask of task states that can be woken
* @wake_flags: wake modifier flags (WF_*)
*
* Conceptually does:
*
* If (@state & @p->state) @p->state = TASK_RUNNING.
*
* If the task was not queued/runnable, also place it back on a runqueue.
*
* This function is atomic against schedule() which would dequeue the task.
*
* It issues a full memory barrier before accessing @p->state, see the comment
* with set_current_state().
*
* Uses p->pi_lock to serialize against concurrent wake-ups.
*
* Relies on p->pi_lock stabilizing:
* - p->sched_class
* - p->cpus_ptr
* - p->sched_task_group
* in order to do migration, see its use of select_task_rq()/set_task_cpu().
*
* Tries really hard to only take one task_rq(p)->lock for performance.
* Takes rq->lock in:
* - ttwu_runnable() -- old rq, unavoidable, see comment there;
* - ttwu_queue() -- new rq, for enqueue of the task;
* - psi_ttwu_dequeue() -- much sadness :-( accounting will kill us.
*
* As a consequence we race really badly with just about everything. See the
* many memory barriers and their comments for details.
*
* Return: %true if @p->state changes (an actual wakeup was done),
* %false otherwise.
*/
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
...抢占任务 (Preempting tasks)
到目前为止,我们了解了上下文切换如何在线程之间自愿发生。接下来我们将看看如何处理抢占。我们将从内核配置为非抢占式的简单情况开始,然后转移到抢占式内核的情况。
非抢占式内核
- 在每个时钟滴答 (tick) 中,内核会检查当前进程的时间片是否耗尽
- 如果发生这种情况,会在中断上下文中设置一个标志
- 在返回用户空间之前,内核会检查此标志并在需要时调用
schedule() - 在这种情况下,当任务在内核模式下运行(例如系统调用)时,不会被抢占,因此不存在同步问题
抢占式内核
在这种情况下,即使我们正在内核模式下运行并执行系统调用,当前任务也可以被抢占。这需要使用特殊的同步原语:preempt_disable 和 preempt_enable。
为了简化抢占式内核的处理,并且由于 SMP 无论如何都需要同步原语,因此在使用自旋锁 (spinlock) 时会自动禁用抢占。
如前所述,如果遇到需要抢占当前任务的条件(其时间片已过期),则会设置一个标志。每当重新激活抢占时(例如通过 spin_unlock() 退出临界区时),都会检查此标志,并在需要时调用调度器来选择新任务。
进程上下文
既然我们已经检查了进程和线程(任务)的实现、上下文切换是如何发生的、我们如何阻塞、唤醒和抢占任务,我们最终可以定义什么是进程上下文以及它的属性:
当内核正在运行系统调用时,它就是在进程上下文中执行。
在进程上下文中,有一个定义明确的上下文,我们可以使用 current 访问当前进程数据。
在进程上下文中,我们可以睡眠(等待条件)。
在进程上下文中,我们可以访问用户空间(除非我们是在内核线程上下文中运行)。
内核线程
有时内核核心或设备驱动程序需要执行阻塞操作,因此它们需要在进程上下文中运行。
内核线程正是用于此目的,是一类特殊的任务,它们不拥有“用户空间”资源(例如没有地址空间或打开的文件)。